Migration of Internal Links to MPLS
The next step in the migration process is to enable MPLS. The size of the MPLS deployment can range from just one link to the whole of the network, and from a limited subset of prefixes to all internal prefixes in the network.
Whichever deployment choice is taken (all the pre-migration steps will have been completed at this time), the tag-switching ip command (or the mpls ip command, if the Cisco Systems, Inc., LDP implementation is used) is the only one necessary on an interface basis to allow MPLS to function between the adjacent LSRs (unless these links are Ethernet links?see the accompanying note). As we have seen in previous chapters, using this command allows the LSR to build a TDP/LDP relationship with any adjacent LSRs and to distribute label bindings across the resultant TCP sessions.
Note
If MPLS is to be deployed across Ethernet links, the additional command tag-switching mtu is necessary within the interface configuration. For further information on the use of this command, refer to Chapter 5, "Advanced MPLS Topics."
Warning
Caution must be taken if a partial migration to an MPLS-based solution approach is used and external routing information is carried within BGP. In this environment, it is absolutely essential to make sure that any routers within the backbone that do not run MPLS (or that do run MPLS, but with a restricted distribution of labels) have the necessary routing information to be capable of forwarding packets that arrive without labels.
In our sample topology, the service provider has adopted a two-stage migration plan for the TransitNet backbone. The first stage is the migration of the network core to an MPLS solution; the second stage is the migration of each POP. Both of these migration steps can be seen in Figure 6-4. Obviously many combinations exist for a successful migration, but because there are no special requirements within the TransitNet backbone to restrict which prefixes are used for label switching, the chosen migration steps are appropriate to achieve a quick and successful transition.
Note
If it is necessary to restrict which prefixes will be used for label switching, you should refer to the section "Controlling the Distribution of Label Mappings," in Chapter 5.
The first-stage migration includes the enabling of MPLS on all backbone links, which include all core routers and the links from each POP border router into the core. The consequence of this is that each of the POP border routers must still hold BGP routes although the core routers do not need BGP routing information anymore because they will label switch all traffic.
Figure 6-4 shows all the necessary BGP sessions for the London POP. Each of the core routers is used to reflect routes between POP sites, so the BGP peering structure is essentially the same, even though the core routers do not actually need the BGP information for successful connectivity between POPs.
Note
An alternative approach to the method shown in Figure 6-4 is to remove BGP from the core completely and define a scheme in which one level of route reflection is used for all edge devices. This reduces the complexity of the BGP design because hierarchical route reflection is no longer a requirement. This also helps to improve BGP convergence time because a BGP route is required to traverse fewer hops. This type of scheme is adequate for many designs, although the scheme shown in Figure 6-4 will be necessary in larger topologies, where the number of BGP speakers and session requirements is high, to allow the BGP topology to scale.
Figure 6-4. TransitNet Migration Strategy
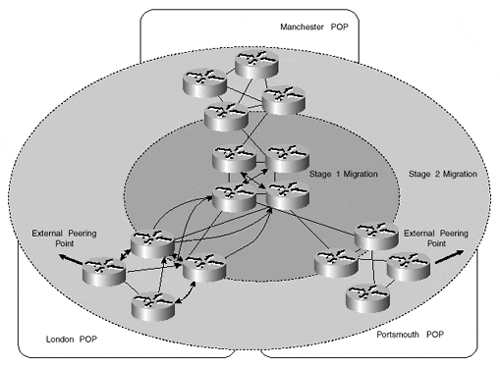
The second-stage migration involves enabling MPLS within each POP in the network. This could be achieved within a select number of POPs, or within every POP. When this migration stage is complete, all traffic entering a POP will be label-switched across the TransitNet backbone to the egress edge router that originated the route within BGP.








