Label Allocation and Distribution Across an ATM-LSR Domain
Label allocation and distribution across an ATM-LSR domain could use the same procedure as the frame-based MPLS world. However, such an implementation would quickly face severe scalability limitations because each label allocated across an LC-ATM interface corresponds to an ATM VC. (Each label has unique VPI/VCI value, and each VPI/VCI value identifies a distinct ATM VC.)
The number of ATM VCs supported across an ATM interface varies between platforms but is rarely higher than approximately 4000 VCs on edge devices (routers), with some hardware platforms supporting only approximately 1000 VCs (for example, PA-A1 port adapter for 7000-series routers). The very small number of VCs supported over an ATM interface makes these circuits a scarce resource that must be tightly controlled. Therefore, the label allocation and distribution over ATM interfaces must be highly conservative.
To ensure that the number of VCs allocated over LC-ATM interfaces stays minimal, upstream LSRs trigger label allocation and distribution over LC-ATM interfaces. An upstream LSR that needs a label to forward labeled packets toward its next hop would explicitly request a label from its downstream LSR.
Note
In most MPLS implementations (including Cisco IOS) of LC-ATM, the labels are requested based on the routing table contents, not on actual data flow, which is the standard MPLS behavior: MPLS is control-driven, not data-driven. These implementations request a label for every destination where the next hop is reachable across the LC-ATM interface.
The downstream LSR could simply allocate a label and respond to the request from the upstream LSR with a corresponding reply message. Under some circumstances, this action would require the downstream LSR to have Layer 3 lookup capability (such as if the downstream LSR would have no further downstream label for the requested destination), which is not the case with ATM switches. Therefore, the ATM switches never respond to a label allocation request unless they already have a corresponding downstream label allocated. If the ATM-LSR has no downstream label that would correspond to the request received from the upstream LSR, it would recursively request a label from its downstream neighbor and reply to the upstream LSR only after receiving a label from the downstream LSR.
The label allocation and distribution process across the ATM-LSR domain has the following characteristics:
Label allocation in devices with Layer 3 lookup capabilities (routers) is done regardless of whether the router has already received a label for the same prefix from its next-hop router. Label allocation in routers is thus called independent control.
Label allocation in devices with no Layer 3 lookup capabilities (ATM switches) is performed only if a corresponding downstream label has already been allocated. Label allocation in ATM switches is thus called ordered control.
The distribution method over LC-ATM interfaces is downstream on demand because an LSR assigns a label across the LC-ATM interface only when that label is specifically requested by an upstream LSR.
To illustrate label allocation and distribution procedures across the ATM-LSR domain, an example from the SuperCell network will be used. The label allocation process for destination X, which is reachable through the New York POP in the SuperCell network, is illustrated in Figure 3-5.
Figure 3-5. Label Allocation in an ATM-LSR Domain
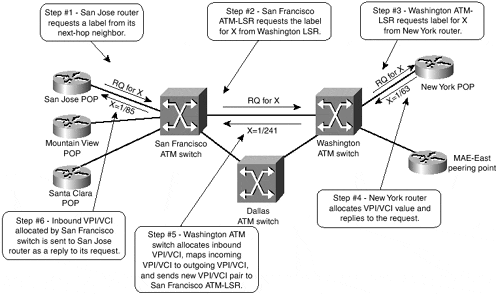
The label allocation and distribution in the SuperCell network is performed in a series of steps:
The San Jose router needs a label for destination X. Its routing table indicates that destination X is reachable through an LC-ATM interface, so it requests a label for this destination from its downstream ATM-LSR.
The San Francisco ATM-LSR is a classical ATM switch operating in ordered control mode, so it requests a label from the Washington ATM switch.
Similarly, the Washington ATM switch requests a label from the New York router.
The New York router operates in independent control mode and can immediately allocate a label (free VC on its LC-ATM interface) for the requested destination. If the New York router already has a downstream label for destination X, it enters the mapping between the allocated VPI/VCI pair and downstream label in its Label Forwarding Information Base (LFIB). Otherwise, it associates a pop operation with the allocated VPI/VCI pair. The VPI/VCI pair allocated to destination X is sent back to the Washington ATM switch in a TDP/LDP reply packet.
After receiving the downstream label allocation, the Washington ATM switch allocates a label for its upstream LSR (yet again, a free VC on the ATM interface leading toward the San Francisco ATM switch) and enters the mapping between the newly allocated VPI/VCI pair and the VPI/VCI pair that it has received from the New York router in its ATM switching matrix. The newly allocated VPI/VCI pair (1/241) is sent to the San Francisco ATM switch in a TDP/LDP reply packet.
The San Francisco ATM switch performs a similar operation, allocates another VPI/VCI pair (1/85), and sends that pair as the label for destination X to the San Jose router.
After receiving a reply to its label allocation request, the San Jose router can enter the VPI/VCI pair received from the San Francisco switch in its Forwarding Information Base (FIB) and in its Label Forwarding Information Base (LFIB).
Note
See Chapter 2 for more information on the processing performed on a router after receiving a label mapping from its downstream neighbor.
VC Merge
Based on the label allocation and distribution rules outlined in the previous section, you might consider a label optimization technique across an ATM-LSR domain. For example, if an ATM-LSR has already received a label for a destination from its downstream neighbor, it might reuse the same downstream label when another upstream LSR asks for the label binding for the same destination. For example, the ATM-LSR in Figure 3-6 might reuse the label already allocated by the router at the right for destination 171.68.0.0/16 when the bottom-left router asks for a label toward that destination.
Figure 3-6. Potential Optimization of ATM Label Allocation
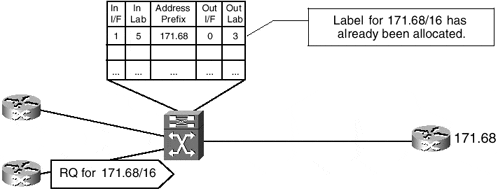
However, if the ATM-LSR tried such an optimization technique, the downstream router would be faced with a tough problem as soon as the ATM cells started arriving simultaneously from both routers at the left, as illustrated in Figure 3-7.
Figure 3-7. Cell Interleaving Problem in an ATM-LSR Domain
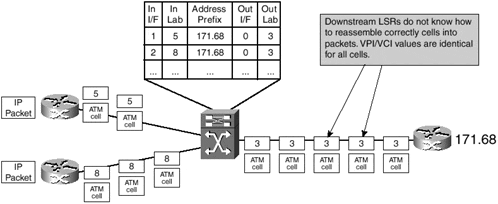
The ATM switch has no means of ensuring that the cells arriving simultaneously from many sources will not be interleaved if they are mapped to the same VC toward the destination. The egress edge LSR obviously cannot resolve the cell interleave because the AAL5 encapsulation used by MPLS contains no additional header fields that would be of any help. AAL5 encapsulation assumes that the cells from different frames will not be interleaved over a VC.
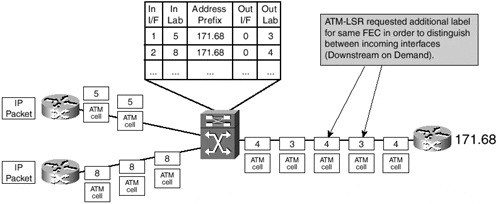
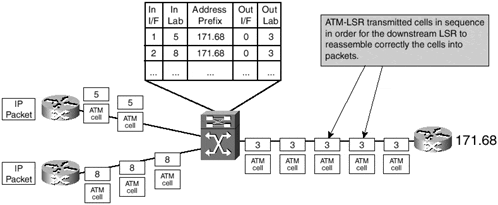
To prevent the cell interleave problem, the ATM-LSR must ask its downstream neighbor for a new label every time an upstream neighbor asks for a label toward any destination, even though it already has some labels allocated for that same destination. This process and the corresponding cell flow are illustrated in Figure 3-8.
Figure 3-8. Cell Flow with Multiple Labels Assigned for the Same Destination
With small hardware modifications, some ATM switches can ensure that two cell flows converging on the same outgoing VC will never get interleaved. These switches buffer incoming ATM cells until they receive a cell with the end-of-frame bit set in the ATM cell header. Then they transmit all the buffered cells on the outgoing VC. This operation effectively turns an ATM switch almost into a frame-based forwarding device, as the additional buffering increases the latency across the switch as well as the buffering requirements of the switch.
The serialization of incoming cell flows onto a single outgoing VC is called virtual circuit merge (VC merge) and allows the ATM-LSRs that support this function to share the same outbound label for a destination among many inbound labels allocated for multiple upstream LSRs, as illustrated in Figure 3-9.
The ATM VC merge function drastically reduces the number of labels allocated across an ATM-LSR domain. For example, consider an IP backbone network in which 100 edge routers are interconnected across an ATM network. Further assume that each edge router announces only 10 subnets into the ATM network (in other words, the router is the egress edge LSR for only 10 destinations). In a traditional ATM MPLS implementation, such a router would have to allocate 10 labels for each ingress router, resulting in 1000 VCs just to support labeled packet forwarding from its upstream neighbors. However, if the ATM network supports VC merge functionality, the egress edge router must allocate only 10 labels because the ATM switches can reuse these labels for all upstream routers.
Figure 3-9. ATM VC Merge
Convergence Across an ATM-LSR Domain
In Chapter 2, you saw that an MPLS deployment in a router-only network does not increase the overall convergence time of the network after a network failure (the convergence time does increase following recovery of a link?see Chapter 2 for more details). On the other hand, the convergence in ATM networks can change considerably when deploying MPLS. In a traditional ATM network, the convergence time consisted of the following components:
An edge router had to detect an adjacent router failure through ATM signaling, ATM operation-and-maintenance (OAM) cells, or routing protocol timeouts (dead timer or hold timer).
The edge router detecting the adjacent router failure immediately propagated the change in network topology to all other routers.
In link-state protocols, all the routers had to recompute a new network topology, usually after a slight delay.
When the ATM network is migrated toward MPLS, the convergence time of the network consists of the following components:
An LSR must detect an adjacent LSR failure. This process is usually very quick because the adjacent LSRs linked with point-to-point links and the physical layer indicates line failure very quickly.
The LSR must propagate change in network topology to other LSRs. This process takes longer in MPLS networks because the number of routing devices between the edges of the ATM network has increased. All ATM switches that were transparent to IP routing in traditional ATM networks now act as IP routers.
All LSRs, including ATM switches, must recalculate the new network topology and change their routing tables.
If the next-hop for a destination has changed, an ATM edge-LSR must request new labels for these destinations. Other ATM-LSRs must propagate these label requests across the ATM-LSR domain, more so if VC merge is not used and each request must be propagated all the way across the ATM network to the egress ATM edge-LSR. This is an extra step that is not needed in traditional ATM networks.
When comparing the convergence of a traditional ATM-based IP backbone with the MPLS-based IP+ATM backbone, you can see that the convergence time in the MPLS-based backbone usually increases because the extra steps were not performed in the traditional IP backbone. The other benefits of MPLS usually outweigh this concern, but the increased convergence time is still a parameter that you must take into account when planning the migration of your ATM backbone toward an MPLS-enabled IP+ATM backbone.







